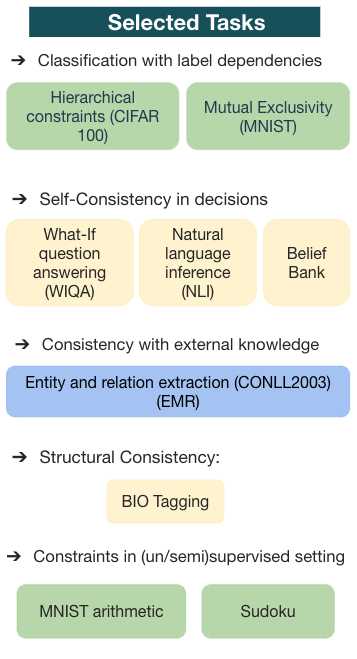
Recent research has shown that integrating domain knowledge in deep learning architectures is effective – it helps reduce the amount of required data, supports reasoning over complex tasks, thus improving the quality of the models’ output, and improves the interpretability of models. However, the research community is missing a convened benchmark for systematically evaluating knowledge integration methods. In this work, we create a collection of benchmarks that includes nine tasks in the domains of natural language processing and computer vision. In all cases, we model external knowledge as {\it constraints}, specify the sources of the constraints for each task, and implement various models that use these constraints. We report the results of these models using a new set of extended evaluation criteria in addition to the task performances for a more in-depth analysis. This effort provides a framework for a more comprehensive and systematic comparison of constraint integration techniques and for identifying the related research challenges. It will facilitate further research for alleviating some problems of state-of-the-art neural models.